This very relevant article suggests an unusual method to improve neural network regularization abilities. I believe that this method has a great potential to enter the standard neural network training toolkit. I was also impressed by the detailed comparison to other methods.
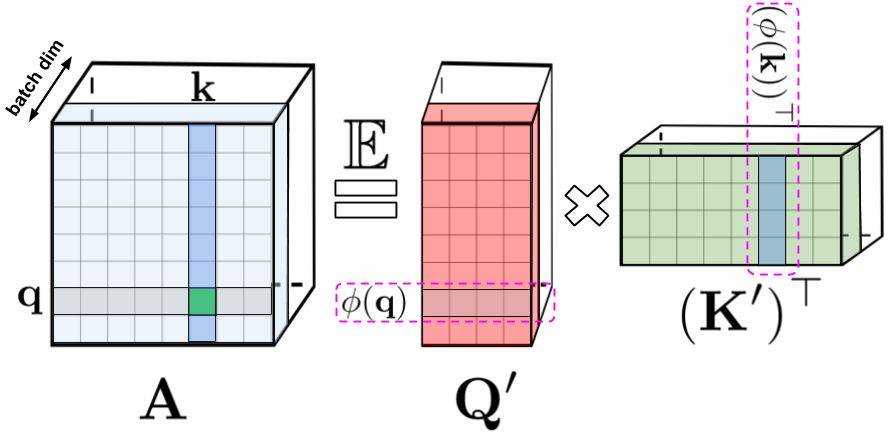
The article suggests a method to lower the Transformer's complexity to a linear order and proves all the arguments also in a rigorous form. The article is not easy to read, but luckily, to understand the main idea, the first 5-6 pages are more than enough.
One of the main challenges in zero-shot learning is enabling compositional generalization to the mode. This review is part of a series of reviews in Machine & Deep Learning that are originally published in Hebrew, aiming to make it accessible in a plain language under the name #DeepNightLearners.